
Abstract
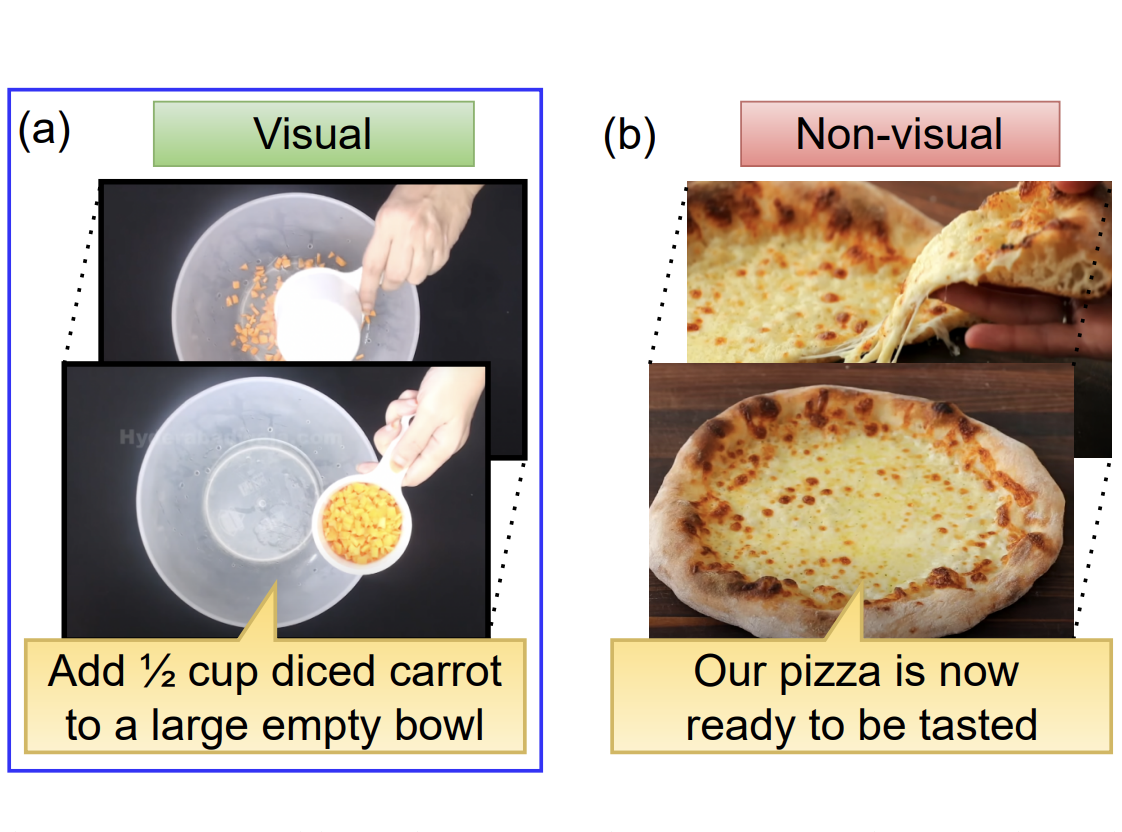
Narrated “how-to” videos have emerged as a promising data source for a wide range of learning problems, from learning visual representations to training robot policies. However, this data is extremely noisy, as the narrations do not always describe the actions demonstrated in the video. To address this problem we introduce the novel task of visual narration detection, which entails determining whether a narration is visually depicted by the actions in the video. We propose “What You Say is What You Show” (WYS^2), a method that leverages multi-modal cues and pseudo-labeling to learn to detect visual narrations with only weakly labeled data. We further generalize our approach to operate on only audio input, learning properties of the narrator’s voice that hint if they are currently doing what they describe. Our model successfully detects visual narrations in in-the-wild videos, outperforming strong baselines, and we demonstrate its impact for state-of-the-art summarization and alignment of instructional video.
Please refer to the ArXiv paper: https://arxiv.org/abs/2301.02307